Det talas ofta om att verksamheter måste få ordning på sin data för att kunna använda AI. Formuleringen är inte fel, men den riskerar att ge en missvisande bild, som om det vore AI-tekniken i sig som ställer kraven.
I själva verket har behovet av strukturerad, spårbar och begriplig information alltid funnits. Det är besluten som kräver ordning på data, inte AI. Skillnaden i dag är att avancerade språkmodeller och andra AI-system gör både styrkor och svagheter i informationsmiljön mycket tydligare, och förstärker dem.
Dokumentet utvecklar tre huvudpoänger: (1) Beslutskvalitet har alltid varit beroende av datakvalitet – oavsett om underlaget tolkas av människor, traditionella IT-system eller moderna AI-modeller. (2) Människor har länge kompenserat för svag informationsmiljö med erfarenhet, magkänsla och informella nätverk, vilket har dolt strukturella problem. (3) AI fungerar som en förstärkare, inte som upphov till kravet på ordning – med bra data ökar AI kapacitet och kvalitet, med dålig data får vi snabbare och mer övertygande fel.
Exemplen är hämtade från offentlig sektor, där behovet av automatisering är stort för att klara framtidens utmaningar, men poängerna gäller lika mycket för andra verksamheter.
Det är inte AI som kräver ordning på data. Det är vi som, om vi vill fatta bättre beslut, behöver ta vår information på allvar.
Bakgrund: Varför pratar alla om data nu?
I takt med att språkmodeller och andra avancerade AI-system blivit mer tillgängliga har intresset för data ökat. I många organisationer låter budskapet ungefär så här: "För att vi ska kunna använda AI måste vi först få ordning på vår data." Underförstått: det är AI-satsningen som skapar behovet.
Verksamheter har i decennier fattat beslut som påverkar människor, ekonomi och samhälle med hjälp av information från många olika källor: verksamhetssystem, dokument, utredningar, rapporter, journaler, mejl, muntliga avstämningar och lokala Excelark. Allt detta är i praktiken data, även om vi inte alltid kallar det så. En hel del av kvaliteten skapas dessutom i stunden – en handläggare som fyller luckor i ett ofullständigt ärende med erfarenhet och ett samtal till en kollega.
Det som händer nu är snarare detta: AI gör det möjligt att använda mycket mer av denna information som underlag för analys och beslut. Samtidigt blir bristerna i informationsmiljön synligare. Ambitionen höjs – fler beslut ska vara datadrivna, mer likvärdiga och bättre motiverade. Gapet mellan ambition och verklighet blir tydligare. Det är lätt att tolka detta som ett "AI-problem", men i grunden handlar det om något mer grundläggande: vilken kvalitet vi accepterar i underlaget för våra beslut.
Beslutskvalitet, inte AI-krav
Det är frestande att låta diskussionen om datakvalitet börja med AI. Ofta formuleras det som att avancerade modeller ställer nya, högre krav på informationen i organisationen. Men redan innan ordet AI dyker upp behöver vi ställa en enklare fråga:
Det kan låta som en semantisk poäng, men skillnaden är praktisk. Att utgå från besluten i stället för tekniken ändrar var arbetet börjar, vem som äger frågan och vad som räknas som framgång. AI-satsningen kan mycket väl vara det som sätter frågan på agendan, men det är beslutens behov, inte tekniken i sig, som avgör vad som faktiskt behöver göras.
Beslutskvalitet handlar om mer än bara data. Vi kan tänka oss beslutsarbetet som ett samspel mellan tre delar: data och information (underlaget som finns dokumenterat i system, dokument och register), tolkning och analys (hur människor och/eller AI bearbetar underlaget och drar slutsatser) och styrning och ansvar (mål, regler, principer och ansvarsförhållanden som omger beslutet).

Tolkning & analys
När vi zoomar in på hörnet tolkning och analys kan vi beskriva kvaliteten med tre grundläggande egenskaper: kontextförståelse (ser vi sammanhanget, eller tolkar vi isolerat och bokstavligt?), metodisk spårbarhet (är det tydligt hur vi kommit fram till en slutsats, eller är analysen en svart låda?) och objektivitet (vilar analysen på sakliga överväganden, eller smyger sig skevheter in?).
Det spelar ingen avgörande roll om analytikern är en människa, ett traditionellt regelbaserat system eller en modern AI-modell. Dessa egenskaper är grundläggande för beslutskvalitet i alla lägen. AI gör utmaningarna med dolda skevheter och svarta lådor mer påtagliga, men det är inte AI som uppfinner kraven på en sund analys. Det är besluten som gör det.
Data & information
När vi zoomar in på hörnet data och information beskrivs kvaliteten med fullständighet (har vi med det väsentliga, eller saknas pusselbitar?), samstämmighet (pekar källorna åt samma håll, eller ger de motstridiga bilder?) och korrekthet (stämmer uppgifterna med verkligheten?).
Om underlaget är ofullständigt blir besluten osäkra. Om det är motsägelsefullt blir de godtyckliga eller beroende av vem som tolkar. Om det är felaktigt riskerar besluten att bli direkt skadliga. När vi talar om att "få ordning på data för att kunna använda AI" handlar det därför i praktiken om något som funnits där hela tiden: att skapa bättre förutsättningar för besluten.
Styrning & ansvar
I hörnet styrning och ansvar handlar kvaliteten om mandat (är det glasklart vem eller vad som har mandat att initiera, bereda och fatta beslutet?), efterlevnad (rimmar processen med lagar, etiska principer och verksamhetens mål?) och redovisningsskyldighet (finns beredskap att förklara, försvara och bära ansvaret i efterhand?).
När vi talar om att reglera och styra AI handlar det om att värna organisationens integritet. AI gör behovet av spelregler och ansvarskedjor mer akut, men det är inte AI som uppfinner kraven på god styrning. Det är besluten som gör det. Det är kvaliteten i de tre hörnen som avgör kvaliteten på besluten – och det är strävan efter bra beslut, inte AI i sig, som bör vara drivande.
Hur människor har maskerat dataproblem
En viktig förklaring till att många organisationer inte upplevt datakvalitet som ett akut problem är att människor länge har fungerat som en buffert mellan rörig information och faktiska beslut. Medarbetare och chefer har fyllt i luckor med erfarenhet, frågat en kollega som "vet hur det brukar vara", gjort kvalificerade gissningar, tolkat vaga formuleringar generöst och byggt egna stödstrukturer i form av Excelark och informella rutiner.
På så sätt har de dagliga besluten kunnat fattas, trots att informationsmiljön varit långt ifrån perfekt. Många dataproblem har därför aldrig formulerats som dataproblem, utan som "sådant vi hanterar i verksamheten".
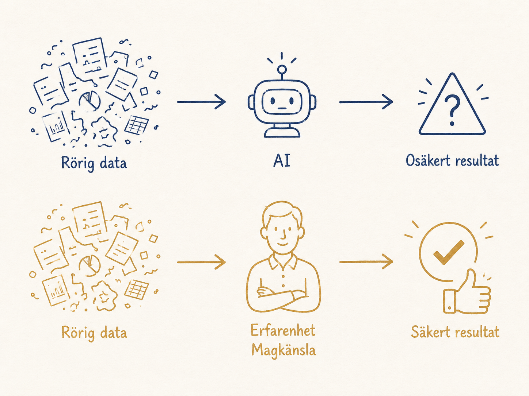
Så länge varje beslut kräver en människa som läser, tolkar, jämför och bedömer underlaget går det att kompensera för en hel del brister – även om det tar tid och energi. När AI införs i denna miljö blir mycket av det som tidigare hanterats tyst och informellt plötsligt synligt. Det upplevs ibland som om AI "ställer högre krav" än människor. Det som egentligen händer är att AI tål mindre begreppslig oordning än en erfaren handläggare, men tål mer teknisk oordning (ostrukturerad text, många källor) – och gör dessutom oordningen tydligare.
Det är värt att stanna vid den skillnaden. AI skapar inte behovet av ordning, men det förskjuter vilken sorts ordning som betalar sig. Den begreppsliga ordningen – att vi faktiskt menar samma sak med samma ord – blir viktigare, medan den rent tekniska formatordningen blir mindre avgörande än många tror. Att få "ordning på data" handlar därför mindre om att städa filservern och mer om att komma överens om vad våra begrepp betyder.
Vad förändras när AI kommer in?

Förstärkt kapacitet
För det första ökar kapaciteten dramatiskt. En människa kan läsa ett begränsat antal dokument per dag. En AI-modell kan på kort tid analysera tusentals handlingar, jämföra mönster, hitta avvikelser och formulera sammanfattningar. Fler beslutsunderlag kan tas fram snabbare, fler alternativ jämföras och fler konsekvenser belysas. Med bra data och genomtänkt användning ger det mer likvärdiga bedömningar, bättre spårbarhet och mer systematisk uppföljning.
Lägre tolerans för oordning
För det andra blir toleransen för oordning lägre. Där en erfaren medarbetare kan "läsa mellan raderna" behandlar en modell texten som den är skriven. Om olika system använder olika definitioner av samma begrepp, om viktiga uppgifter saknas eller om dokumentationen varierar kraftigt, kommer AI att förstärka detta. Resultatet blir mer ojämna förslag och risk för felaktiga slutsatser. Det kan kännas som att AI ställer orimliga krav, men egentligen synliggör den krav som fanns där tidigare – om vi vill kunna förstå, motivera och följa upp besluten.
AI mer spegel än motor
Det leder till en tredje förändring: AI fungerar mer som en spegel än som en motor. Som spegel gör AI befintliga mönster i data och arbetssätt tydligare. Som motor kan AI förstärka dessa mönster, vare sig de är bra eller dåliga. Har organisationen genomtänkta processer och god datakvalitet kan AI bidra till högre kapacitet och bättre beslutsstöd. Är informationsmiljön fragmenterad och svagt dokumenterad riskerar AI att förstärka just detta – men snabbare och mer övertygande.
Data governance i AI-eran: samma frågor, ny skala
Begreppet "data governance" kan låta avskilt från verksamheten. I praktiken handlar det om grundläggande frågor: Vilka begrepp använder vi när vi beskriver det vi beslutar om – elev, kund, patient, ärende, insats? Var lagras dessa uppgifter, och på vilket sätt? Vem ansvarar för att de är uppdaterade och begripliga? Hur kan vi följa ett beslut bakåt till vilket underlag som användes?
Dessa frågor är inte nya. Det som förändras i AI-eran är skala och synlighet: fler datakällor blir användbara i beslutsunderlag (fritext, pdf:er, mejl), fler beslut påverkas direkt av hur data är definierad, och fler aktörer är beroende av att samma begrepp betyder samma sak.
- Om "elev" definieras olika i två system blir det svårt att göra en samlad analys av skolresultat.
- Om "ärendeavslut" betyder en sak i ett system och något annat i ett annat blir uppföljning av handläggningstider osäker.
- Om det inte går att se när en uppgift senast uppdaterades blir det svårt att bedöma hur användbar den är.
När AI kommer in blir konsekvenserna av otydligheter större. Den goda nyheten är att AI också kan hjälpa till att upptäcka dem.
Så går ni vidare – praktiska rekommendationer
1. Börja med besluten, inte med tekniken
I stället för att börja med "Hur kan vi använda AI i vår data?" kan ni börja med: "Vilka beslut vill vi kunna fatta bättre, och vilket underlag saknas i dag?" Vilka beslut har stor påverkan på människor, ekonomi eller kvalitet? Hur ser underlaget ut konkret i dag? Vilka brister upplever medarbetarna? Genom att utgå från besluten blir det tydligare vilka dataproblem som är mest akuta och vilka AI-tillämpningar som faktiskt gör nytta.
2. Synliggör dagens beslutspraktik
Många beslut tas inte enbart i formella processer – de fattas i mötesrum, vid skrivbord, i telefonsamtal och mejltrådar. Kartlägg vilka beslut som tas var, av vem och på vilket underlag. Förstå vilka informella lösningar som används för att kompensera för brister. Detta är inte en kritik mot medarbetare, tvärtom en möjlighet att systematisera deras erfarenhet och göra den till en resurs i stället för en tyst buffert.
3. Skilj på "AI som kollega" och "AI som del av beslutsmotorn"
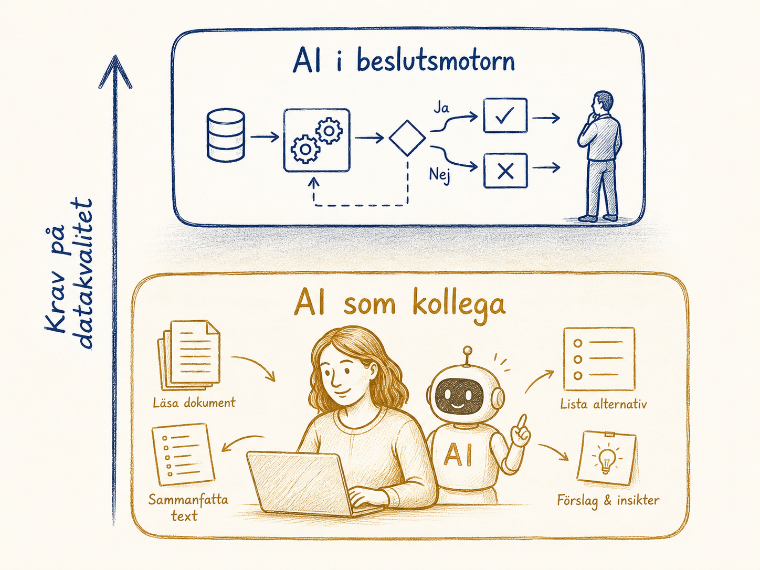
AI som kollega stöttar medarbetare – sammanfattar texter, föreslår formuleringar, listar risker, förklarar samband. En människa tar det slutliga beslutet och bär ansvaret. AI som del av beslutsmotorn är integrerad i själva processen – prioriterar och klassificerar ärenden, genererar beslutsförslag som oftast följs, eller fattar automatiska beslut. Här behöver kraven på datakvalitet, spårbarhet, transparens och uppföljning vara betydligt högre.
Ju närmare beslutet AI flyttas, desto mer aktualiseras rättsliga krav – till exempel förvaltningslagens motiveringsskyldighet och de skärpta kraven i EU AI Act för högrisktillämpningar. Att tydliggöra vilken roll AI har gör det enklare att ställa rätt frågor om data, processer, ansvar och etik.
4. Använd AI för att stärka informationsmiljön
AI behöver inte bara vara konsument av data – den kan också användas för att förbättra informationsmiljön: upptäcka inkonsekvenser i hur begrepp används, föreslå mer enhetliga begrepp och strukturer, hjälpa till att skapa datakataloger och analysera vilka uppgifter som faktiskt används i beslut jämfört med vilka som samlas in. På så sätt blir AI en del av lösningen, inte bara beroende av att problemen redan är lösta.
Avslutning: AI som spegel, inte ursäkt
Det kan vara frestande att beskriva datakvalitet som ett "AI-krav" och därmed något som drivs av ny teknik. Men i grunden handlar det om något mer grundläggande: Vilken nivå av underbyggnad accepterar vi för beslut som påverkar människor och samhälle? Hur vill vi kunna motivera våra beslut, både nu och i efterhand? Vilken roll ska fakta, analys och spårbarhet spela i vår styrning?
AI-tekniken gör dessa frågor mer brännande, men den uppfinner dem inte. Den gör det svårare att skjuta dem framför sig, eftersom den visar upp konsekvenserna av våra informationsmiljöer i större skala och högre hastighet.
Detta dokument är framtaget av Olausson Advisory och innehåller generella analyser och rekommendationer. Innehållet utgör inte juridisk rådgivning och bör anpassas efter varje organisations specifika förutsättningar.
← Tillbaka till Kunskapsbank